AI赋能的Live2D数字人实现
最初是在B站刷到这个视频数字人的 All in Dify,试着docker-compose本地部署了一下项目, dify云服务+qwen2.5模型工作流编排了一个简单的对话功能,并开启了语音与文字互转,但是demo里的人物模型只有嘴巴张合,没有复杂的口型功能,总感觉差些意思,看了下Cubism Live2D的官网示例,京(Kei)这个模型有唇形同步功能,于是就开始了对原项目大刀阔斧得修改
原项目的部署方式就不做过多介绍了,参考原文档:AWESOME-DIGITAL-HUMAN-部署指南。
之前想过使用pixi-live2d-display库,但是它最高支持的live2d模型版本是4.x,最新的Cubism Editor版本都已经5.2了,官方最新的唇形同步功能也要求模型版本是5.x,所以放弃了。
但是官方的demo极其难用,sdk for web的文档也很简陋,源码的注释也是日文为主,所以为了避免出现做一半结果版本对不上的问题,就直接以CubismWebMotionSyncComponents为基础建立自己的项目,因为这个项目缺失模型的鼠标交互功能,于是把CubismWebSamples的代码也合并进来,并将两个项目的引用的sdk代码也合并进源码,确保版本一致。
我就说下我使用的部署方案以及需要注意的几个点:
- 首先需要准备以下环境:node 20+,python 3.10+,docker-compose,dify账号(我使用的是云服务,私有部署可忽略,参考原文档),Cubism Editor 5.x(不想改动直接使用官网模型可忽略)
- 原项目的docker-compose提供了两个服务,一个是后端服务adh_server,一个是前端服务adh_web,我的做法是只保留后端服务,因为原项目前端是用我不喜欢的react实现的,而且核心代码与框架关系不大,就用我更喜欢的vue重构了😅。
- dify创建空白应用的时候记得选Chatflow,而不是工作流,熟悉dify玩法的可忽略我的建议~
- 大模型要选支持tts的
- 前端服务需要开启https,Web Audio API需要运行在安全的上下文环境
- 下载最新版的Cubism SDK for Web,这是Live2D的js运行时,用于在 Web 平台上实现 Cubism 模型的各种功能,如模型的生成、更新、销毁,运动数据的应用,参数混合以及图形绘制等
- 下载最新版的Cubism SDK MotionSync Plugin for Web,这是Cubism SDK for Web的一个插件,可以分析音频数据实时生成对应的口形动作。
- 下载CubismWebSamples和CubismWebMotionSyncComponents,前者是
Cubism SDK for Web的使用案例,后者是Cubism SDK MotionSync Plugin for Web的使用案例
实现页面效果如下:
核心实现要点
一、编辑器相关
在
Cubism Editor里的动画界面通过文件->导出运行时文件->导出动态文件,导出目录里得到一个.moc3后缀的文件,双击打开或者拖到Cubism Viewer里打开,再将导出的.motion3.json文件拖进来,即可双击预览动画效果;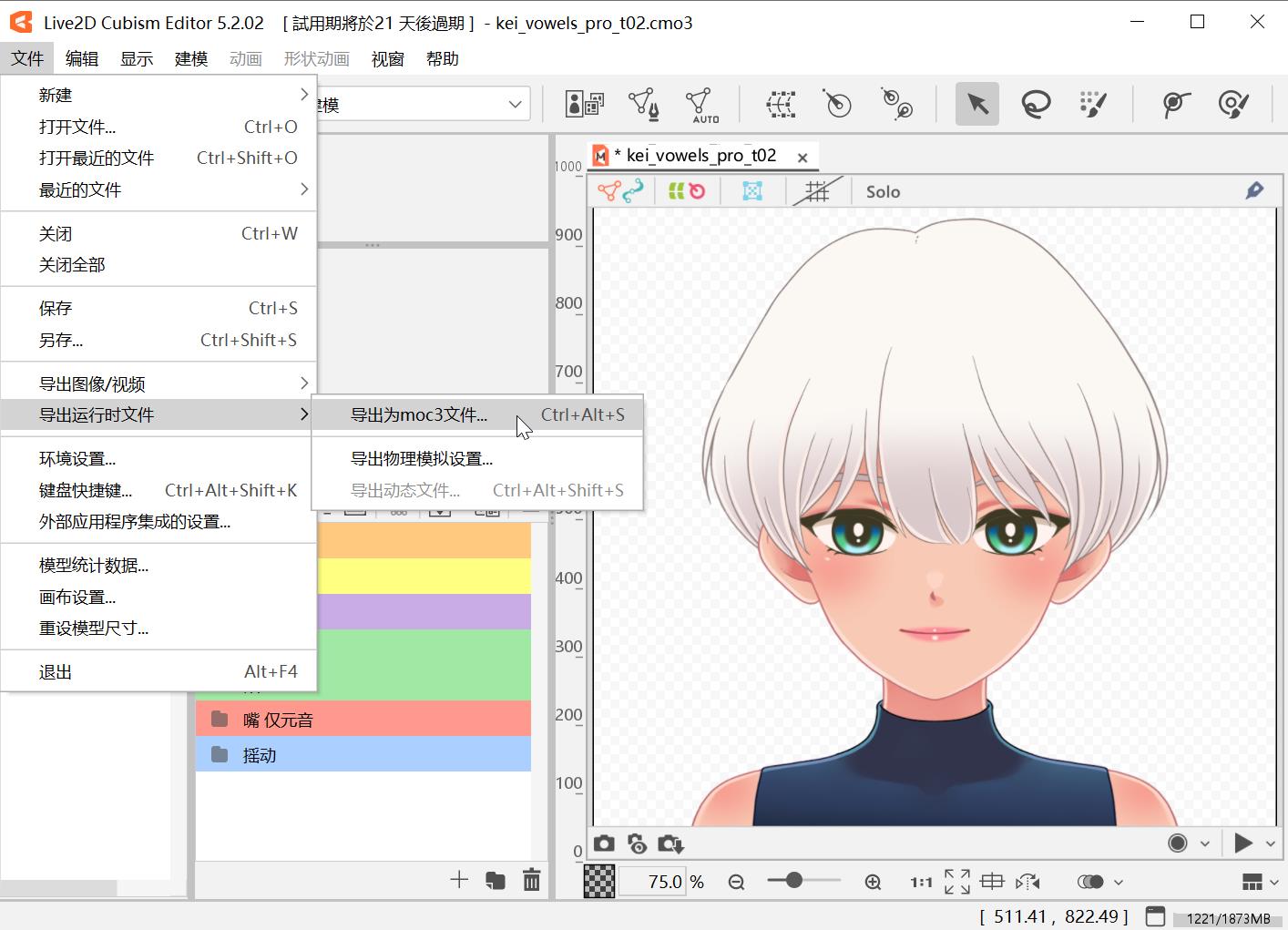
在
Cubism Viewer里给动作设置分组,即可根据组名和下标获取动作文件,使用sdk在网页上播放动作;在
Cubism Viewer里的动作参数里选择一个音频文件,即可使用sdk在网页触发动作时播放音频;在
Cubism Editor里的参数面板选择自动眨眼和口型同步的设置,勾选眨眼和口型同步的需要的参数,导出的.motion3.json文件会有Groups字段:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17"Groups": [
{
"Target": "Parameter",
"Name": "EyeBlink",
"Ids": [
"ParamEyeLOpen",
"ParamEyeROpen"
]
},
{
"Target": "Parameter",
"Name": "LipSync",
"Ids": [
"ParamMouthOpenY"
]
}
]sdk会自动播放眨眼动画,也会自动使用lappwavfilehandler.ts处理动作的wav音频文件,生成口形(仅开闭)。
在
Cubism Editor里的参数面板选择动态同步设置,设置CRI音频分析的参数(采样率、混合率、平滑化),并映射模型里制作的AIUEO这五个元音,这时候导出,会有一个.motionsync3.json文件,用于将音频映射到唇形
二、音频处理
只要
.motion3.json文件有LipSync组,动作文件里有音频,sdk会调用lappwavfilehandler.ts的start方法开始解析音频数据,并在动画主循环里调用getRms方法更新口形开闭状态。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* 动画主循环
*/
public update(): void {
// ...
// 口形同步设置
if (this._lipsync) {
let value = 0.0; // 实时进行口形同步时,从系统获取音量,并输入0~1范围内的值。
this._wavFileHandler.update(deltaTimeSeconds);
value = this._wavFileHandler.getRms();
for (let i = 0; i < this._lipSyncIds.getSize(); ++i) {
this._model.addParameterValueById(this._lipSyncIds.at(i), value, 0.8);
}
}
// ...
}上面是
CubismWebSamples里的口型同步的实现,需要更精细的唇形,就需要参考CubismWebMotionSyncComponents了,这里的音频有两种处理,一个是从文件获取音频源,一个是从麦克风获取从文件获取音频源并解析
通过lappmotionsyncaudiomanager.ts的createAudioFromFile将音频载入AudioContext,在动画循环中对帧间的音频进行采样,将完整采样片段添加到声音缓冲区,通过调用this._motionSync.updateParameters(this._model, audioDeltaTime),使用CubismMotionSyncProcessorCRI对缓冲区的音频片段进行分析,设置唇形;从麦克风获取音频源并解析
在模型初始化时,通过
LAppInputDevice.getInstance().initialize()来请求麦克风权限,创建默认空缓冲区,建立音频处理管道,音频工作线程处理器(lappaudioworkletprocessor.js)将原始音频数据转换为Float32Array格式,通过postMessage发送给主线程进行进一步处理(用于口型同步分析)1
2
3
4
5const audioBuffer = Float32Array.from([...input]);
this.port.postMessage({
eventType: "data",
audioBuffer: audioBuffer,
});同时将输入样本逐帧复制到输出,实现音频信号的直通输出,避免播放静音
1
2
3
4
5
6
7
8
9
10let inputArray = inputs[0];
let output = outputs[0];
for (let currentChannel = 0; currentChannel < inputArray.length; ++currentChannel) {
let inputChannel = inputArray[currentChannel];
let outputChannel = output[currentChannel];
for (let i = 0; i < inputChannel.length; ++i){
outputChannel[i] = inputChannel[i];
}
}
return true;主线程通过
AudioWorkletNode.port.onmessage拿到AudioBuffer后,添加到缓冲区末尾,在动画循环中通过this._motionSync.setSoundBuffer(0, this._audioBufferProvider.getBuffer(), 0)供sdk设置唇形;
使用AI进行文字转语音并进行唇形同步
与AI的交流类比麦克风的实时通话更符合直觉,为音频处理单独开辟一个线程也能有更好的性能,所以我决定基于CubismWebMotionSyncComponents中从麦克风获取音频源的方法进行二次开发。模仿
LAppInputDevice类,创建一个新类TTSAudioBufferProvider实现ILAppAudioBufferProvider接口将AI文字转音频接口返回的音频base64转化为Blob,从该Blob创建虚拟媒体流来模拟麦克风输入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 创建音频元素
const audioElement = new Audio();
audioElement.src = URL.createObjectURL(new Blob([base64ToArrayBuffer(base64Data)], {type: 'audio/wav'}));
audioElement.controls = false;
// 创建MediaStream目的地
const mediaStreamDestination = this._context.createMediaStreamDestination();
// 创建MediaElementSource节点
const sourceNode = this._context.createMediaElementSource(audioElement);
sourceNode.connect(mediaStreamDestination);
audioElement.onended = async () => {
// 监听播放结束
};
// 监听播放错误
audioElement.onerror = (event) => {
console.error('音频播放错误:', event);
};
await audioElement.play();
return mediaStreamDestination.stream;创建短暂的静音音频流来模拟停顿
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45public createSilentAudio(duration: number = 0.2): string {
// 创建一个短暂的静音音频(200ms)
const sampleRate = 44100; // 采样率
const channels = 1; // 单声道
const samples = Math.floor(duration * sampleRate);
// 创建 WAV 文件头
const header = new ArrayBuffer(44);
const view = new DataView(header);
// RIFF 头
view.setUint32(0, 0x52494646, false); // "RIFF"
view.setUint32(4, 36 + samples * 2, true); // 文件大小
view.setUint32(8, 0x57415645, false); // "WAVE"
// fmt 子块
view.setUint32(12, 0x666d7420, false); // "fmt "
view.setUint32(16, 16, true); // 子块大小
view.setUint16(20, 1, true); // PCM 格式
view.setUint16(22, channels, true); // 声道数
view.setUint32(24, sampleRate, true); // 采样率
view.setUint32(28, sampleRate * channels * 2, true); // 字节率
view.setUint16(32, channels * 2, true); // 块对齐
view.setUint16(34, 16, true); // 位深度
// data 子块
view.setUint32(36, 0x64617461, false); // "data"
view.setUint32(40, samples * 2, true); // 数据大小
// 创建静音数据(所有值为0)
const data = new Int16Array(samples);
// 合并头和静音数据
const wavData = new Uint8Array(header.byteLength + data.byteLength);
wavData.set(new Uint8Array(header), 0);
wavData.set(new Uint8Array(data.buffer), 44);
// 转换为 Base64
let binary = '';
for (let i = 0; i < wavData.length; i++) {
binary += String.fromCharCode(wavData[i]);
}
return `data:audio/wav;base64,${window.btoa(binary)}`;
}在音频片段播放结束回调(audioElement.onended)里播放静音音频,然后在其播放结束回调(silentElement.onended)里播放下一个音频片段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18audioElement.onended = async () => {
// ...
// 创建并播放短暂的静音音频
const silentElement = new Audio(this.createSilentAudio());
const silentSource = this._context.createMediaElementSource(silentElement);
silentSource.connect(mediaStreamDestination);
await silentElement.play();
// 静音结束后才真正结束
silentElement.onended = () => {
// ...
this._isPlaying = false;
this._nextExpectedIndex = this._currentPlayingIndex + 1;
this.stopPlayback();
this._playNextIfPossible();
};
}对文本按标点符号进行分割,分段请求tts接口;
音频流的接口响应顺序不确定,需要确保音频片段顺序播放,所以每次获取音频片段后,放入队列并按照片段编号进行排序,若第一个片顿的编号就是当前寻找的编号,不是则退出,播放完后移出片段,寻找下一个编号;
每一次对话可能会被用户发起的下一次对话打断,所以通过sessionId来判断时效性,只有当前对话的sessionId与当前的sessionId一致时,才会播放音频片段。
由于浏览器的限制,音频播放必须要在用户的交互中触发,增加按钮,当用户点击时播放一段静音音频以启用音频功能:
1
2
3
4
5
6
7
8
9const enableAudio = async () => {
const ttsProvider = TTSAudioBufferProvider.getInstance();
await ttsProvider.initialize();
// 触发一次虚拟播放以解除浏览器限制
const silentAudio = ttsProvider.createSilentAudio(0.1);
const silentElement = new Audio(silentAudio);
await silentElement.play();
console.log('音频功能已启用');
}
